Visits: 29
Meine alte Heizung ist ausgefallen. Die wurde von einer Junkers TRQ21 gesteuert – was nichts anderes war als ein Thermostat, der für eine Wärmeanforderung 24V auf die Steuerleitung legt.
Da bei mir der Thermostat in der Küche hängt, die am wenigsten geheizt wird, ist die Steuerung für meine anderen Räume suboptimal. Ich hatte den Thermostat weiter in Betrieb, damit der für Frostschutz funktioniert, aber ich hatte zusätzlich einen Raspberry Pi, der mittels eines einfachen Scheduling-Systems und einer simplen Weboberfläche den Thermostat überbrücken konnte, und einfach die volle Spannung auf die Steuerleitung legte, wenn ich es wärmer haben wollte.
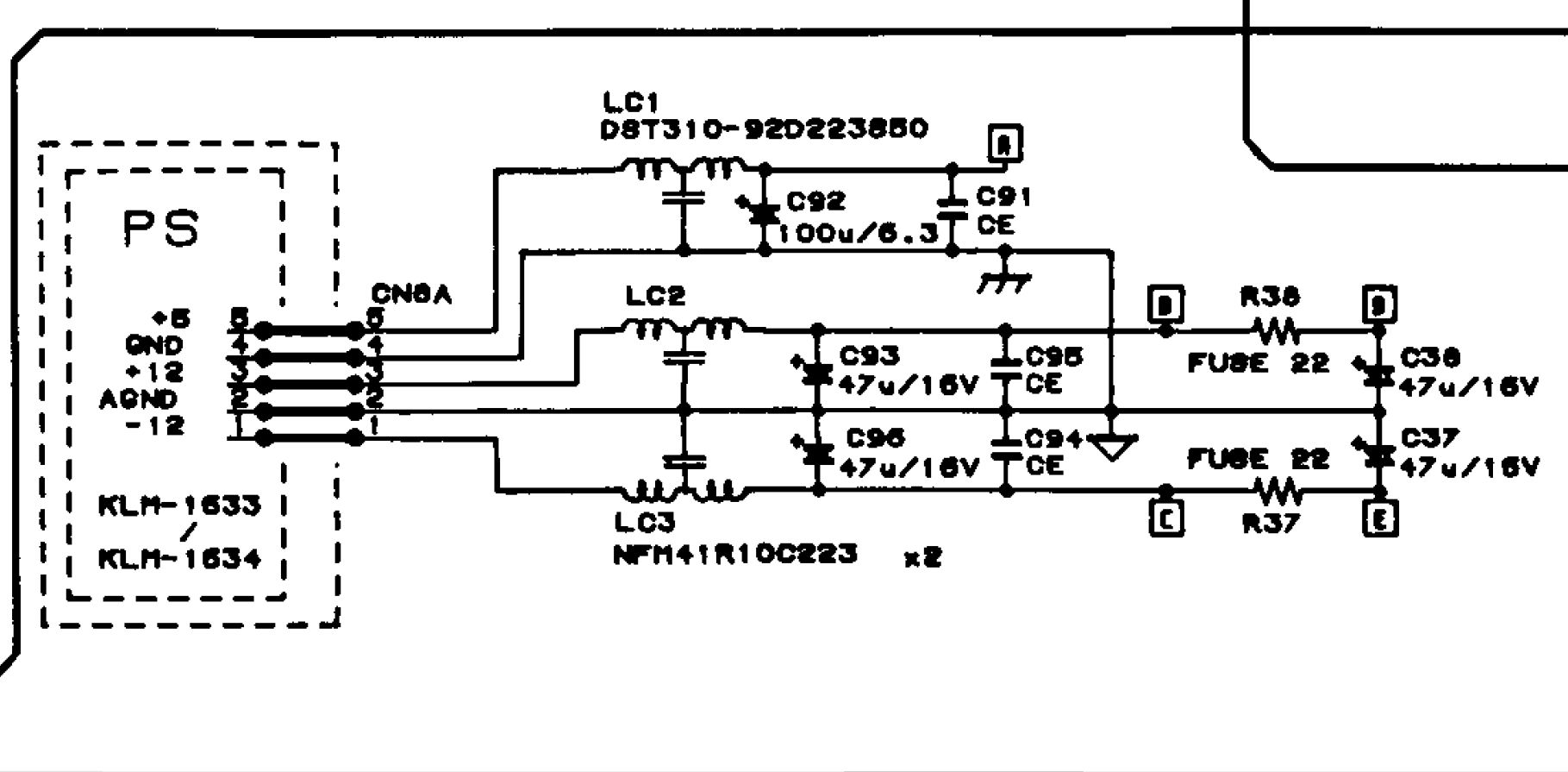
Die neue Heizung, eine Bosch Condens 5300i, hat (leider) eine EMS Steuerung, was zwar technisch viel besser ist, aber es schwieriger macht, mit selbstgebauten Systemen eine Fernsteuerung umzusetzen.
Grundsätzlich kann der Raspberry Pi die Daten vom Bus lesen, er braucht aber einen Pegel von 0V (0) bzw. 3,3V (1). Der EMS-Bus liefert bei mir gemessen 10V (0) und 15V (1). Bei kbza.de fand ich den Bauplan für einen Pegelwandler, der jetzt bei mir auch so läuft. Ich habe nur für R1 10kΩ genommen, da meine Messungen ergaben, dass meine Schaltung schon bei etwas unter 10V einen HIGH Pegel ergab, mit 10kΩ statt 8,2kΩ schaltet es bei mir zuverlässig und das Ergebnissignal sieht auf dem Oszilloskop sehr gut aus.
Auf der Webseite ist auch ein Python-Skript, das allerdings für mich nicht funktioniert. Das Skript selber ist auch nicht ein Beispiel für gute Programmierung, aber immerhin ein Hinweisgeber.
Das Skript erkannte keine der Nachrichten, die bei mir vom EMS Bus kommen. Eine extrem vereinfachte Form liefert die eingehenden Daten als Hexwerte:
#!/usr/bin/env python
# -*- coding: iso-8859-1 -*-
import time
import serial
import sys
ser = serial.Serial(
port='/dev/ttyAMA0',
baudrate = 9600,
parity=serial.PARITY_NONE,
stopbits=serial.STOPBITS_ONE,
bytesize=serial.EIGHTBITS,
timeout=1
)
while 1:
char = ser.read()
hex = char.encode('HEX')
sys.stdout.write(hex + ' ');
sys.stdout.flush()
Bei mir kommt dann z.B. folgendes raus:
89 00 08 00 88 00 09 00 89 00 12 00 18 00 98 00 08 00 88 00 08 00 88 00 13 00 09 00 89 00 08 00 88 00 09 00 89 00 14 00 18 00 98 00 08 00 88 00 08 00 88 00 15 00 09 00 89 00 08 00 88 00 09 00 89 00 16 00 18 00 98 00 08 00 88 00 08 00 88 00 17 00 09 00 89 00 08 00 88 00 09 00 89 00 20 00 18 00 98 00 08 00 88 00 08 00 88 00 28 00 09 00 89 00 08 00 88 00 09 00 89 00 30 00 18 00 98 00 08 00 88 00 08 00 88 00 38 00 09 00 89 00 08 00 88 00 09 00 89 00 40 00 18 00 98 00 08 00 88 00 08 00 88 00 48 00 09 00 89 00 08 00 88 00 09 00 89 00 50 00 18 00 98 00 08 00 88 00 08 00 88 00 58 00 09 00 89 00 08 00 88 00 09 00 89 00 60 00 18 00 98 00 08 00 88 00 08 00 88 00 68 00 09 00 89 00 08 00 88 00 09 00 89 00 0a 00 18 00 98 00 08 00 88 00 08 00 88 00 0b 00 09 00 89 00 08 00 88 00 09 00 89 00 0c 00 18 00 98 00 08 00 88 00 08 00 88 00 0d 00 09 00 89 00 08 00 88 00 09 00 89 00 0e 00 18 00 98 00 08 00 88 00 08 00 88 00 0f 00 09 00 89 00 08 00 88 00 09 00 89 00 10 00 18 00 98 00 08 00 88 00 08 00 88 00 11 00 09 00 89 00 08 00 88 00 e4 00 10 20 2d 2d 00 c8 40 02 84 64 12 03 00 02 6e 00 00 80 00 00 87 0f 00 02 83 00 00 02 00 88 00 e4 23 00 01 54 00 9a 12 64 f9 00 88 00 e3 00 01 00 01 00 00 00 00 00 00 00 00 02 84 12 64 46 00 40 00 00 0e 00 88 00 09 00 89 00 12 00 18 00 98 00 08 00 88 00 e9 00 00 80 00 80 00 00 00 00 00 46 3c 00 00 00 00 10 ba 00 01 cf 00 00 00 05 02 00 3c 00 88 00 08 00 88 00 13 00 09 00 89 00 08 00 88 00 09 00 89 00 14 00 18 00 98 00 08 00 88 00 08 00 88 00 15 00 09 00 89 00 08 00 88 00 09 00 89 00 16 00 18 00 98 00 08 00 88 00 08 00 88 00 17 00 09 00 89 00 08 00 88 00 09 00 89 00 19 00 18 00 98 00 08 00 88 00 08 00 88 00 21 00 09 00 89 00 08 00 88 00 09 00 89 00 29 00 18 00 98 00 08 00 88 00 08 00 88 00 31 00 09 00 89 00 08 00 88 00 09 00 89 00 39 00 18 00 98 00 08 00 88 00 08 00 88 00 41 00 09 00 89 00 08 00 88 00 09 00 89 00 49 00 18 00 98 00 08 00 88 00 08 00 88 00 51 00 09 00 89 00 08 00 88 00 09 00 89 00 59 00 18 00 98 00 08 00 88 00 08 00 88 00 61 00 09 00 89 00 08 00 88 00 09 00 89 00 69 00 18 00 98 00 08 00 88 00 08 00 88 00 0a 00 09 00 89 00 08 00 88 00 09 00 89 00 0b 00 18 00 98 00 08 00 88 00 08 00 88 00 0c 00 09 00 89 00 08 00 88 00 09 00 89 00 0d 00 18 00 98 00 08 00 88 00 08 00 88 00 0e 00 09 00 89 00 08 00 88 00 09 00 89 00 0f 00 18 00 98 00 08 00 88 00 08 00 88 00 10 00 09 00 89 00 08 00 88 00 09 00 89 00 11 00 18 00 98 00 08 00 88 00 08 00 88 00 12 00 09 00 89 00 08 00 88 00 09 00 89 00 13 00 18 00 98 00 08 00 88 00 08 00 88 00 14 00 09 00 89 00 08 00 88 00
Nichts sieht so aus wie die “Header”, die das Originalskript suchte. Den Beschreibungen im EMS Wiki scheine ich auch nicht zu verstehen. Wenn ich mir nur 08 00 88 00 09 00 89 00 ansehe, macht das im Moment keinen Sinn. Was ich glaube zu verstehen ist dass eine Nachricht, in der das oberste Bit in der Empfänger-ID gesetzt ist, gefolgt von einem BREAK, eine dringende Anfrage an die entsprechende ID ist. Die Antwort – wenn es nichts zu senden gibt – ist die ID ohne das oberste Bit, gefolgt von einem BREAK.
08 ist eine ID – wenn ich das richtig verstehe sollte das die ID des Brenners sein. 00 kann ein Break sein, oder eine echte 0. Danach aber kommt 88 (= 08 + bit 7) gefolgt von 00.
Was ist ein BREAK frage ich mich da – das ist ein Byte mit Wert 0 und nicht gesetztem Stop-Bit, oder auch: die Leitung liegt relativ lange auf 0. Das serial Modul von Python kann diese Unterscheidung nicht liefern, allerdings kann der PL011 UART im Raspberry Pi das erkennen.
Mit cat /proc/tty/driver/ttyAMA kann man die Anzahl von Breaks sehen, die entdeckt wurden während Daten vom seriellen Port gelesen wurden:
0: uart:PL011 rev2 mmio:0x20201000 irq:81 tx:0 rx:2663 brk:1154 oe:1 CTS
Im Schnitt kam es also etwa auf 2 1/2 empfangenen Bytes ein Break. Wenn ich die Daten oben genauer ansehe, dann scheint es oft zu sein, dass eine ID (mit und ohne 7. Bit) kommt, dann 00 gelesen wird, dann wieder ID und 00. Dann gibt es noch ein paar Bereiche, die mehr nach sinnvollen Daten aussehen. Grob geschätzt würde ich glauben, dass fast alle als 00 gelesene Bytes in Wirklichkeit Breaks sind.
Natürlich könnte ich mir bei BBQKees Electronics ein EMS-Gateway kaufen, das soll alles wichtige können, aber ich würde gerne das Problem für mich selber lösen.
Also: wie komme ich an die Info vom UART, dass wir einen Break und keine 0 haben?